
问题描述
SQuAD数据集是斯坦福大学发布的公开数据集,提供train和dev训练集,未公开test数据集。该数据集上的数据给定一段passage和一个Question,求取Answer,Answer为文中出现的一个东西,Passage、Question 和Answer对如下所示。
Passage: Tesla later approached Morgan to ask for more funds to build a more powerful transmitter. When asked where all the money had gone, Tesla responded by saying that he was affected by the Panic of 1901, which he (Morgan) had caused. Morgan was shocked by the reminder of his part in the stock market crash and by Tesla’s breach of contract by asking for more funds. Tesla wrote another plea to Morgan, but it was also fruitless. Morgan still owed Tesla money on the original agreement, and Tesla had been facing foreclosure even before construction of the tower began.
Question: On what did Tesla blame for the loss of the initial money?
Answer: Panic of 1901
模型结构
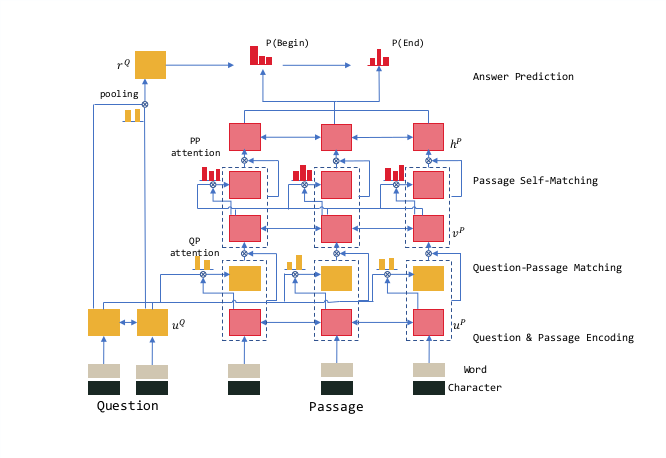
模型看起来很复杂,其实主要就是对attention的运用,而且对attention运用了非常多的次数,个人感觉此结构对给定的passage和question进行了非常深入的挖掘,但是仅仅是对文本本身的挖掘,和语义理解没有什么关系。由于文中用到了attention来对passage和question(passage)进行match,最后用pointer networks来选择答案,所以下面对前面的文章由远到近的讲一下。
Neural Machine Translation by Jointly Learning to Align and Translate
原论文是用于解决机器翻译的问题,结构如下

简单推导(本文主题不在此,简单介绍): 定义条件概率: 其中是RNN的hidden state,y是翻译的输出,x是输入,通过 计算,向量由处理输入的BiRNN的隐藏状态决定, , 权重通过 计算且,这个函数用于对第j个位置的输入和第i个位置的输出打分,看看他们之间有多match,原文是用一个神经网络train的,后面的用于解决QA问题的一般都是直接计算的,用一个矩阵表示。如在论文Text Understanding with the Attention Sum Reader Network中的方法:
- We compute a vector embedding of the query.
- We compute a vector embedding of each indi-vidual word in the context of the whole doc-ument (contextual embedding).
- Using a dot product between the question embedding and the contextual embedding of each occurrence of a candidate answer in the document, we select the most likely answer.
Pointer Networks
在该论文中将上面的attention的具体计算方法直接给出了,此为对第i个输出计算,,分别便是encoder和decoder的hidden states:
第二步的softmax即将转化成attention。
文中提出的Ptr-Net将attention的那一步直接替换成输入的每个token做为输出的概率,即:
这种结构在解决输出的内容在输入中出现非常好用。
Learning Natural Language Inference with LSTM
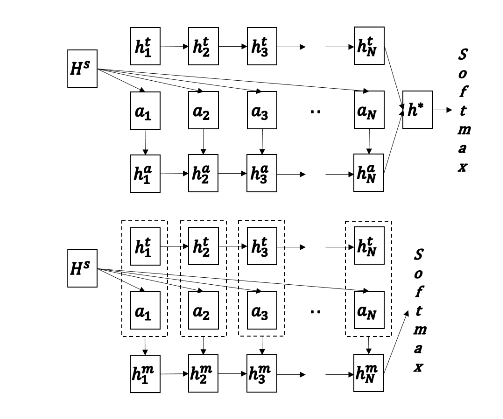
此文本来是用来解决natural language inference的问题的,在上半部分是前人提出的attention机制,“A dog jumping for a Frisbee in the snow.” and the hypothesis “A cat washes his face and whiskers with his front paw.” 在该句子中dog和cat不匹配,应该被记住,最后得出两个句子关系为contradiction,但是上面的结构直接由最终状态得出结论效果不好(距离太长容易忘记),所以受到lstm的启发,在向后传的时候增加了几个门,用于控制记忆和遗忘。正是用了这些门机制(和LSTM的门非常类似,这里不再写出),所以该结构称之为Match-LSTM。
Machine Comprehension Using Match-LSTM and Answer Pointer
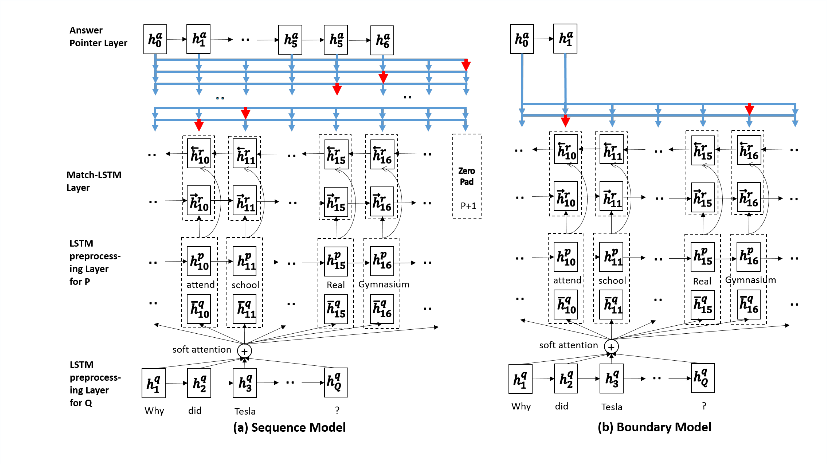
上图即此论文提出的结构,最下面是将问题过一个LSTM,第二层是将原文过一次LSTM,然后通过上文提到的Match-LSTM方法处理,再通过Pointer Networks获得输出,左半边是原来的pointer networks,右边的是直接截取一个开始点和一个终止点得到答案。最终的loss function如下:
R-net
有了之前的铺垫,R-net就很好理解了,下面的Question-Passage Matching(QPM)就是之前提到的Match-LSTM,中间加了一个Passage Self-Matching,最后通过Pointer Networks预测输出。
R-net的主要的创新点就在提出了Passage Self-Matching,因为QPM只用到了问题和文章局部信息,并未挖掘文章本身信息之间的关联,所以加入了一个self attention之后效果很好。




